Web测试相关文献
2019年1月blog汇总
dot生成图
1 | dot -Tpng -o hello.png draw_graph.dot |
建模Ajax应用
在 Ajax技术出现之前的Web系统的建模过程中,通常 的方法是将一张网页、一个构件等表示为Web模型的一个状 态。当发生超链接、表单提交、构件调用等同步请求时,会 触发当前网页跳转到下一个网页或者由一个构件跳转到一个 网页或者另一个构件,从而引起Web模型的状态迁移。
而在基于Ajax技术的Web应用中网页内通常会包含异 步的请求。通常,Ajax请求的结果只是引起原网页内局部内 容的刷新并不会使原网页跳转到其它网页或构件。当网页内 有多个不同Ajax请求分别引起网页内不同部分内容的局部 刷新时,其中的一个请求发生后就会造成整张网页的内容与 原网页内容不同,网页内显示的内容会因为不同的Ajax请求 的发生产生不同的组合结果。
状态之间只通过同步请求的方式进行迁移
提出将Web应用的一张网页划分为能局部刷新的各个部分, 根据这些部分的内容的变化将网页分成多个不同的状态进行建模。
网页状态元素:将会随着Ajax请求产生的结果局部刷新内容的部分定义为网页状态元素e$_i$,网页状态元素可以是网页中局部的信息、表格数据、超链接、排序方式等所有可以被动态修改的内容,一张网页中包含的所有网页状态元素的集合为e={e0,e2,…..ei+1}
网页状态元素的Ajax操作集:将能引起网页状态元素ei内容发生变化的Ajax请求操作定义为ajax-op$_{ij}$,其中下标i表示第i个网页状态元素,j表示在e$_i$上的第j种Ajax请求操作。
网页状态元素值域:由于网页状态元素的内容会随着在它之上的Ajax请求而改变,因此每个网页状态元素会有一个值域。将网页状态元素e$i$的值域描述成c$_i$={c${i0}$,c${i1}$,…,c${ij}$,}下标的i表示网页的第i个网页状态元素e$_i$,j表示e$_i$的第j种取值。规定网页状态元素的特殊取值Null,当取值为Null时表示网页在当前状态下不显示该网页状态元素。
使用计算树逻辑(CTL)来设计系统的陷阱性质,对系统的可达性、活性、安全性进行检验。
系统可达性指系统中的每一个状态节点都至少能被访问到一次。状态覆盖准则检验。
系统活性指系统中每一条迁移都至少能被访问到一次。迁移覆盖准则来检验。
系统的安全性指系统不存在非法的导航,迁移组合覆盖准则来检验。
反馈导向探索Web应用程序以推导测试模型
feedback-directed /depth-first/ breadth-first/ random exploration
许多工业级web应用有巨大的状态空间和详尽的爬虫,状态空间爆炸问题。
测试模型的四个方面:code coverage impact, navigational diversity, page structural diversity, test model size.即代码覆盖影响、导航多样性、页面结构多样性、测试模型的大小。
Web2.0应用用户接口状态改变:
1、事件驱动2、由客户端应用程序代码的执行引起的3、通过在浏览器中动态改变内部DOM树来表示
有效性的不同表现:functionality Coverage.navigational coverage.page structural coverage

[12]. Reducing the size of the test model can decrease both the cost of maintaining the generated test suite and the number of test cases that must be rerun after changes are made to the software 。


Given a Web 2.0 application, a maximum exploration time t, and a maximum number of states to explore n, the intent is to maximize the test model coverage while reducing the model size within t.
探索策略中使用了贪心算法。
步骤:
1.对于每个部分展开状态,计算相对于其他未展开状态的状态分数(第4-6行),该状态的得分是该状态的最低成对状态得分。
2.选择具有最高准确度(得分)值的状态作为下一个要扩展的状态(第8行)
3.在选择的扩展状态中,根据事件得分确定事件的优先级(第9行)
4.使浏览器进入所选状态,并根据优先顺序执行排名最高的事件(第10-13行)
5.如果在事件执行后更改了DOM状态,则相应地更新SFG(第14-16行),并调用Explore过程(第17行)
可以说明,主要考虑客户端地代码覆盖率。
有限状态机
我们根据Web应用程序用户界面事件对应用程序状态转换行为的影响将其分为四组:
1.self-loop一个事件不改变DOM的状态.例如刷新页面或者清除表单数据。
2.state-independent event一个事件总是导致相同的结果状态。例如事件的结果总是Index Page
3.A state-dependent event状态有关事件:一个事件在它第一次执行后,在从相同状态触发时始终导致相同状态的事件。
4.Nondeterministic event不确定性事件: 无论从何处触发,都可能导致新状态的事件,当从相同状态触发时,这样的事件可以导致不同的状态。
crawljax默认引擎支持深度优先和广度(多线程,多浏览器)爬行策略。[19]
六个JS的开源项目:

要从不同领域选择web应用程序以支持结论:gallery,task management,game,editor
对于每个视图更改,仅在客户端和服务器之间交换状态更改,而不是多页Web应用程序中的整页检索方法。
Web开发人员现在可以按照更加直观的单页面用户界面(UI)基于组件的方式编写应用程序,例如Java AWT和Swing,而不是根据Web页面的顺序进行思考。

1.检索页面
2.导航路径提取3.UI组件模型标识
4.单页UI模型定义
5.目标UI模型转换

静态分析可以检查页面并找到指向其他内部页面的href链接。 动态分析可以帮助检索需要特定请求参数的页面(基于表单)。例如,通过基于场景的测试用例或收集与web应用程序交互的用户动作(例如,会话,输入数据)的跟踪。 很明显,我们检索到的镜像副本与实际的Web应用程序类似,我们的导航路径和UI组件识别就越好。
导航路径的提取:
导航路径是用户在浏览Web应用程序时可以在页面上的链接之后执行的路径。 对于ajaxi fi cation,获得对此导航路径的理解对于能够在单页用户界面模型中建模导航至关重要。 例如,知道类别页面与产品项目列表页面链接,意味着在我们的单页面模型中,我们需要一个可以导航到产品项目列表UI组件的类别UI组件。
在浏览Web应用程序时,结构更改,强制页面非常小,我们可以立即注意到我们正在浏览属于特定类别的页面,例如产品列表。 将这些类似页面分类为一组,简化了我们的导航模型。 我们的假设是这样的分类也提供了一种更好的模型来搜索候选用户界面组件。
就HTML源代码而言,这意味着A和B中的大量代码是相同的,并且只有一小部分代码是B中的新代码。我们人类在浏览应用程序时将其区分为更改。
我们可以简单地更新需要用B中的新分数替换的A部分。因此,来自页面B的这部分代码在我们的目标系统中成为一个UI组件。 候选组件的识别列表以及导航模型将帮助我们定义单页用户界面模型。
这个抽象模型应该能够捕获动态变化,这些应用程序中需要的导航路径,以及抽象的一般Ajax组件,例如Button,Window,Modal,如图3.1所示。
拥有抽象用户界面模型的优点是我们可以将其转换为不同的Ajax设置。 我们已经探索了许多Ajax框架,例如Backbase,Echo2和GWT,并且已经开始进行研究以采用模型驱动的Ajax方法(Gharavi et al。,2008)。
这要求我们对页面进行分组,这些页面足够相似并且可以从给定页面直接访问。
Web页面相似度:
可以根据目标视图所需的模型以多种不同方式对网页进行分类
Textual Identity如果它们具有完全相同的HTML代码,则认为两个页面相同
Syntactical Identity根据语法树的比较,对具有完全相同结构的页面进行分组,忽略标记之间的文本
Syntactical Similarity根据在页面的语法树上计算的相似性度量,分类具有相似结构的页面
文本和句法身份分类概念在查找属于特定类别的页面时具有有限的能力,因为它们寻找完全匹配。 Syntactical Similarity是一种概念,它可以帮助我们通过定义两个页面被认为是克隆的相似性阈值来将页面聚类成有用的组。
schema-based similarity.

在具有一组链接节点的树结构中,每个节点表示具有零个或多个子节点的网页,并且边表示到其他页面的web链接。 我们相信树结构可以为Web应用程序的导航路径提供简单但清晰且易于理解的抽象视图。
显示了我们基于模式的集群过程。 从给定的根节点(例如,index.html)开始,目标是通过在每个导航级别上聚类类似的页面来提取导航路径。
请务必注意,我们不会立即对所有页面进行聚类。 相反,我们沿着导航路径行走,对于每个节点,我们将与该节点链接的页面进行聚类。 随着导航路径进行聚类非常重要,因为我们希望恢复界面中的更改,然后确定候选UI组件。 如果我们将所有页面聚类为一个级别,那么导航信息将会丢失,这是我们试图避免的。
cloc代码统计工具命令行
cloc使用规范:命令行下
1 | cloc-1.80.exe src(要检查的文件) |
遗传算法
遗传算法适合大海捞针,可以并行运算,离散型的,如反潜艇搜索。神经网络是黑箱模拟,适合无确定规律性的,如下围棋,有神经网络芯片,离散型的。粒子群算法是散弹,适合撒网捕鱼,解决目标难有行踪问题,如用于投资撒网,离散型的。模拟退火是跳山搜索,防止陷入局部最优解,适合组合优化问题,并行运算难。对于遗传算法,神经网络通用性比较强,研究应用比较多。深度学习的崛起,让神经网络在解决复杂难建模如图像识别,围棋,语音等领域应用方兴未艾。现代智能算法,往往结合大数据平台,gpu运算,并行计算,HPC,多模式结合等手段,来完成更加复杂多变的业务需求。
常用的智能算法如下,可以结合使用:
基于仿生/模拟算法:
人工神经网络深度学习
遗传算法
人工免疫算法
蚁群算法
粒子群算法
人工鱼群算法
文化算法
禁忌搜索算法
模拟退火算法
基于数学理论算法:
线性规划回归分析
梯度下降
K近邻算法
SVM支持向量机
朴素贝叶斯
决策树
图论算法
并行算法
模糊数学
混沌算法
马尔可夫链
作者:find goo
链接:https://www.zhihu.com/question/29762576/answer/131582624
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
测试数据部分
测试数据可以分为两类,包括正面和负面测试数据。
正测试数据用于验证给定函数的特定输入是否导致预期结果。 进行负面测试以检查程序处理异常和意外输入的能力。
可以是从先前操作中获取的实际数据,也可以是专门为此目的设计的一组人工数据。
测试数据的生成方式:
1.Manual Test Data Generation
2.Automated Test Data Generation
自动化测试数据创建的主要好处之一是高精度。 使用这种技术还有更好的速度和输出。 该技术的最佳方面是它可以在没有任何人为干预的情况下以及在非工作时间内执行。 反过来,这有助于节省大量时间以及生成大量准确数据。
3.Back-end Data Injection后端数据注入
后端数据注入技术利用大型数据库提供的后端服务器。 这是因为可以使用存储在数据库中的测试数据直接更新现有数据库,这反过来又可以通过SQL查询快速获得大量数据。 但是,这种测试数据生成技术消除了对前端数据输入的需要,应该确保这一点得到了极大的关注和谨慎,以避免任何形式的数据库关系。
4.Third-Party Tools
市场上很容易获得的第三方工具是创建数据并将其注入系统的好方法。 这些工具完全了解后端应用程序数据,使这些工具能够抽取类似于实时场景的数据。 因此,它为测试人员提供了大量的大量数据。
使用第三方工具的主要好处是提供的数据的准确性。 这是由于工具对系统和领域的透彻理解。 另一个优点是在处理回溯数据填充方面,允许用户对历史数据执行所有必需的测试。 此外,执行这些测试并不需要具备详细的领域知识和专业知识。
5.Path wise Test Data Generators路径测试数据生成器
被认为是生成测试数据的最佳技术之一,该技术为用户提供了一种特定的方法,而不是多条路径,以避免混淆。 使用此技术可帮助用户获得特定和更好的知识,并预测其覆盖范围。 该技术使用户输入要测试的程序,以及测试它的标准,例如路径覆盖,语句覆盖等。
Web应用状态流图的生成过程
1.初始化
提供web应用入口、所需测试数据和设定测试终止条件等。
2.请求
首次请求一般通过URL直接访问Web服务器,后续的请求主要通过内置浏览器模拟用户操作进行发送。
3.响应解析
数据信息主要指HTML代码,其包含的超链接、鼠标点击和表单提交等事件将会被分析成新的请求依据不同的搜索策略放入栈或队列,供后续触发。同时,根据不同的页面分组策略,可以将HTML代码抽象成DOM树,对页面进行分组并加入到状态流图中。
4.终止条件判定
如果满足初始化阶段设置的终止条件,则终止本次测试并输出测试结果。
5.获得新请求
6.发送请求
重复3、4、5、6,直到满足测试终止条件
web应用自动化测试框架实现
事件控制器:
1.接收新的请求,并加入请求队列和堆栈,并模拟用户行为,将请求从队列或堆栈中移出,通过加入和移出操作生成测试用例。
2.根据系统所设置的单个测试用例终止条件,判断当前的测试用例生成过程是否可以终止。当DOM分析器发现环路、页面错误或达到单个测试用例运行的时间上限时,终止当前测试用例的运行。
3.还原系统测试环境。将数据库和服务器恢复到测试开始时的设置。主要包括还原数据库和清理浏览器的Session和Cookie信息,必要的时候重启web应用服务器。
4.根据系统设置的全局终止条件,决定本次测试是否终止。全局终止条件主要包括测试时间上限、请求栈或队列中是否还有未触发的请求和测试的请求深度等。
导航图构造算法
导航图的构造算法

导航图中的一些定义:G=<N,E>,测试路径p=<ns,es,pr>
|es|=|ns|-1
e$i$=<n,m>属于es,n$_i$=n属于ns,n${i+1}$=m属于ns,pr是参数名序列
Page定义部分:

- sidebar部分:url变化,通过url跳转
每一个url定义为一个page。
- navbar部分:静态,登出以及管理员账号维护部分。
- tags-view-container:标签部分,刷新以及标签关闭等,url不变。
- search部分:公用方法,传入的参数变化,其url不变。
定义在basePage中。
- add部分:额外方法,url不变仅窗口弹出。
分别定义在Page中的方法。
- app-main部分:结果展示部分,局部刷新Ajax.
检验DOM树的状态。
测试数据生成部分:
提取参数名以及参数对应的约束,主要分配给公共方法以及额外方法部分。
测试用例生成部分:
初始化LoginPage和HomePage,沿着导航图的路径传入参数生成测试用例。
并行处理测试用例:
并发执行:多浏览器、多线程执行(后期应用于大型web应用)
解耦以及抽象。
并行分割路径的两种方法:
url跳转的分为一类(顺序执行)、
调用公共方法无url跳转的分为一类(顺序执行),可以同步执行。
评估标准:
导航图的状态数量states,转换数transitions.
PO对象的代码行数LOC,PO的总数量、以及导航方法数量。
litemall-admin的src的代码行数:

PO对象的代码:

测试数据生成中定义约束:
染色体是一个可变长度的导航方法调用序列,每个调用都具有调用所需的实际参数值。引导测试用例生成的精确度函数基于执行序列与当前覆盖目标集之间的距离。
每个导航方法应该指定安全执行的前提:
这种情况可能取决于调用参数值以及应用程序的状态,该状态由在先前导航步骤中对应用程序执行的动作确定。
可以通过静态代码分析获得参数范围。
页面相似度
表单数据是用户事先录入数据库,在测试执行的时候按照不同的组合算法生成不同的表单测试用例。



比较网页结构相似度
一般网页分为三类:
- 目录导航式页面(List\Index Page)
- 详细页面(Detail Page)
- 未知页面(Unknown Page)
网页本身可以抽象成串行节点或者是DOM树,对于串行序列,可以用最长公共子序列来衡量相似度。
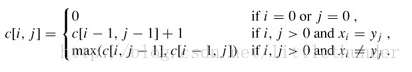
1 | 网页相似度的计算: |
xpath进行页面相似度比较
DOM结构的相似性公式

我们从来自相同Xpath位置的每个新页面提取一个链接。
通常页面相似性比较都是比较网页URL并进行模式搜索,而本文不是比较URL,而是比较原始Web文档中入站链接的XPath地址。
用于选择和提取数据的建模HTML树和XPath语言被证明是在实际数据提取应用中非常有用的技术。
本文使用XPATH表达式选择内部站点链接。
pq-gram distance


bag of XPath string
common paths distance(CPD)

breadth-first crawling strategy
first-in-first-out method

为了创建一个由网页组成的数据集,其中包含有关内部链接的所需附加信息,我们编写了一个基本的网站爬虫。 我们利用广度优先爬行方法,首先抓取所有相邻网页。 这与深度优先爬行相反,优先考虑在回溯之前沿着每个链接分支尽可能地探索网站。 据证明[35],以广度优先搜索顺序遍历Web图是一种很好的爬行策略,因为它倾向于在爬行的早期发现高质量的页面。 已实施的爬网程序不使用cookie并且是单线程的,因此适合一次从一个站点下载一个页面。 但是,在爬网过程中,我们运行了多个爬虫实例 - 每个实例用于不同的Web站点。 爬网算法包含URL清理过程,该过程删除强制会话ID令牌,例如phpsessid,cfid,aspsessionid.
网页中xpath的提取:
安装beautifulsoup的过程:
1 | pip install beautifulsoup4 |
XPATH:



- Web site crawling
- link extraction
- URL and XPath tuple generation
获取动态网页DOM树:
1 | import time |
参考:
https://www.jb51.net/article/128560.htm
https://segmentfault.com/q/1010000004867625/a-1020000004867910
https://blog.csdn.net/Together_CZ/article/details/74015599
https://cuiqingcai.com/2621.html
一个完整的 Web 应用信息提取流程中应当具有以下两个步骤:页面导航过程和数据抽取过程。
- 页面集合(Page Set,PS)-> POs
- 页面导航路径(Page Navigation Path,PNP)
- 页面数据(Page Data,PD)
页面导航过程和数据抽取过程
同一个URL对应不同页面xpath
选用广度优先算法:程序健壮性好,信息提取算法并行执行

初步思考改造:
1 | unvisitedPOQueen 待访问的PO存储集合 |
等价类划分PO对象
黑盒角度对页面节点和迁移边分类:
普通页面节点:这类页面不存在和用户交互的输入点。
输入页面节点:这类页面存在和用户交互的输入点,不同的输入可能会导致不同的页面迁移
链接迁移边:表示页面之间的迁移是通过点击超链接来完成
按钮迁移边:表示页面之间的迁移是通过点击按钮来完成触发的
页面节点:PO相当于一堆xpath集合操作
PageObject对象生成

基于PO的测试用例生成:
通过TESTGENERATOR函数提取PO对象的公共方法来产生测试用例,方法池和对象池用来存储和提供测试用例所必需的元素。通过测试生成的每一次迭代,我们的方法可以捕获新的DOM状态,由修改程序引入现有网页或通过链接到新网页。我们的方法再为新捕获的DOM状态产生新的pageobjects对象。
创建PO对象:
扩展了框架feed-back directed random testing去为po产生测试用例。迭代一直到满足测试准则。
将初始页面对象集作为输入,测试生成器首先初始化方法池和对象池(第3行和第4行)。 使用输入页面对象中的公共方法初始化方法池。 对象池最初填充有随机原始值,例如常量数值和字符串文字,以及用于初始化浏览器实例的预定义语句。 初始化之后,测试生成器从方法池(第6行)中随机选择一个被测方法(MUT)。 为了生成测试用例,测试生成器在对象池中搜索MUT的输入参数。 然后它将MUT与作为测试生成的输入参数提供的找到的对象连接起来(第7行)。 每个测试用例在生成时执行(第8行)。 如果通过,则将其添加到输出测试用例集T中,并将其结果对象作为输入对象放入对象池以进行进一步的迭代(第9到12行)。

相比之下,自动生成的页面对象通常将页面元素映射到成员字段,并为元素上的所有可能操作创建成员方法。
除了识别新的DOM状态并存储其网页代码之外,我们的技术还记录了导致每个新DOM状态的方法序列。 在新网页的测试用例中,记录的方法序列是初始化DOM和浏览器实例所必需的。 在当前测试生成完成之后(即,满足停止标准),测试生成器输出生成的测试用例和新发现的网页以及信息(例如URL,方法序列)以创建DOM状态。
但是,Web界面的固定抽象限制了测试工具可以涵盖的功能范围。同时产生了测试用例和Page Object对象。可以自动覆盖客户端代码,探索新的DOM状态并且检测web应用的错误。理想情况下,测试用例应测试同一功能组中Web元素的事件或操作组合,因为跨组合通常不相关或无效。一种可能的解决方案是对网页进行程序分析,识别功能组,为各个功能组生成细粒度的页面对象,并控制方法序列的生成。
现阶段测试JS和AJAX应用的技术方法和特点:它们执行随机测试以生成测试输入,并使用在执行期间提取的信息来生成新输入。我们采用反馈定向随机测试来生成测试用例并逐步探索更多状态。
- 通过去除不相关的方法序列组合来提高测试生成性能
- 研究页面对象抽象范围对测试有效性的影响。
在测试生成的第一次迭代之前,我们的技术自动为被测Web应用程序的主页(例如,index.html,index.php)创建一组初始页面对象。 页面对象生成器分析网页以提取Web元素并使用这些元素生成页面对象的字段和公共方法。
网页功能测试的检查要领
超级链接:
检查每一个链接的正确跳转,查找孤页
表单:
表单是指网页中用于输入和选择信息的文本框、列表框和其他域。域的大小能不能正确,能不能接受正确数据,拒绝不正确数据。
功能测试:
Web站点的功能是贵公司雇佣开发人员而不只是艺术家的原因。就是这一部分与服务器通讯并且最终完成任务。
⑵链接
链接是使用户从一个页面浏览到另一个页面的重要手段。对于每个链接,需要验证两件事情: 一是该链接将用户带到它所说明的地方,另外就是被链接页面是存在的。这句话听起来有些问题,但是有很多多站点的内部链接都是空的。这实在是无法忍受。
⑶表单
当用户通过表单提交信息的时候,都希望表单能正常工作。如果使用表单来进行在线注册,要确保提交按钮能正常工作,当注册完成后应返回注册成功的消息。如果使用表单收集配送信息,应确保程序能够正确处理这些数据,最后能让顾客能让客户收到包裹。要测试这些程序,需要验证服务器能正确保存这些数据,而且后台运行的程序能正确解释和使用这些信息。
⑷数据校验
如果系根据业务规则需要对用户输入进行校验,需要保证这些校验功能正常工作。例如,省份的字段可以用一个有效列表进行校验。在这种情况下,需要验证列表完整而且程序正确调用了该列表(例如在列表中添加一个测试值,确定系统能够接受这个测试值)。
⑸Cookies
很多用户喜欢甜食,但是开发人员喜欢web cookie (小甜饼)。如果系统使用了cookie,测试人员需要对它们进行检测。如果在cookies中保存了注册信息,请确认该cookie能够正常工作而且已对这些信息已经加密。如果使用cookie来统计次数,需要验证次数累计正确。
⑹应用程序特定的功能需求
最重要的是,测试人员需要对应用程序特定的功能需求进行验证。尝试用户可能进行的所有操作:
下订单、更改订单、取消订单、核对订单状态、在货物发送之前更改送货信息、在线支付等等。这是用户之所以使用网站的原因,一定要确认网站能像广告宣传的那样神奇。
软件模块划分的好处
(1) 使程序实现的逻辑更加清晰,可读性强。
(2) 使多人合作开发的分工更加明确,容易控制。
(3) 能充分利用可以重用的代码。
(4) 抽象出可公用的模块,可维护性强,以避免同一处修改在多个地方出现。
(5) 系统运行可方便地选择不同的流程。
(6) 可基于模块化设计优秀的遗留系统,方便的组装开发新的相似系统,甚至一个全新的系统。
功能模块划分
- 登录模块以及注销模块
- 信息查找模块
- 信息查找结果显示模块
- 信息查找结果操作模块
- 信息添加模块
- 信息显示模块
- 链接跳转模块
- 外链等其他功能模块
页面对象抽象
LoginPage LogoutPage
login() logout()
SearchPage
所有服务的search统一为一种方法search,通过传入不同参数进行不同页面的search操作。模板模式。
ResultSearchPage
ResultActionPage
编辑//*[@id=”app”]/div/div[2]/section/div/div[2]/div[3]/table/tbody/tr[1]/td[8]/div/button[1]
删除//*[@id=”app”]/div/div[2]/section/div/div[2]/div[3]/table/tbody/tr[1]/td[8]/div/button[2]
- AddPage
页面内弹窗形式的添加,URL地址不改变。统一add方法,传入不同参数。
//*[@id=”app”]/div/div[2]/section/div/div[4]/div/div[2]/form/div[1]/div/div/input用户
//*[@id=”app”]/div/div[2]/section/div/div[4]/div/div[2]/form/div[1]/div/div/input广告
页面跳转形式的添加,URL地址改变。单独创建add_product方法。
//*[@id=”app”]/div/div[2]/section/div/div[1]/div/form/div[1]/div/div/input商品
- ViewPage
非重要功能测试
- JumpPage
验证链接跳转的正确性
- ExternalLinkPage
同上
详细功能
用户管理服务:
- 会员管理服务,见AdminUserController类
查找(用户名,手机号)、添加、导出
数据的编辑、删除
- 收货地址服务,见AdminAddressController类
查找(用户ID、收货人名称)、导出
- 会员收藏服务,见AdminCollectController类
查找(用户ID、商品ID)、导出
- 会员足迹服务,见AdminFootprintController类
查找(用户ID、商品ID)、导出
- 搜索历史服务,见AdminHistoryController类
查找(用户ID、搜索历史关键字)、导出
- 意见反馈服务,见AdminFeedbackController类
查找(用户名、反馈ID)、导出
商场管理服务:
- 行政区域服务,见AdminRegionController类
查找(行政区域名称、行政区域编码)、导出
- 品牌制造商服务,见AdminBrandController类
查找(品牌商ID、品牌商名称)、导出
- 商品类目服务,见AdminCategoryController类
查找(类目ID、类目名称)、添加、导出
- 订单管理服务,见AdminOrderController类
查找(用户ID、订单编号、订单编号)、导出
- 通用问题服务,见AdminIssueController类
查找(问题)、添加、导出
- 关键词服务,见AdminKeywordController类
查找(关键字、跳转链接)、添加、导出
商品管理服务
商品服务,见AdminAdminController类
商品列表
查找(商品编号、商品名称)、添加(跳转到商品上架页)、导出
商品评论
查找(用户ID\商品ID)、导出。
推广管理服务
- 广告服务,见AdminAdController类
查找(广告标题、广告内容)、添加、导出
- 专题服务,见AdminTopicController类
查找(专题标题、专题子标题)、添加、导出
- 团购服务,见AdminGrouponController类
查找(商品编号)、添加、导出
系统管理服务
- 管理员服务,见AdminAdminController类
查找(管理员名称)、添加、导出
- 对象存储服务,见见AdminStorageController类
查找(对象KEY,对象名称)、导出
其他服务
- 统计服务,见AdminStatController类
- 个人服务,见AdminProfileController类
显示类。
外链:
现代前后端分离应用创建的web应用特点
现代JS框架存在的根本原因是保持UI与状态同步
Vue.js和JQuery的区别在于声明式和命令式,当应用在运行时,内部状态会不断的发生变化,这时用户页面的某个局部区域需要不停的重新渲染。中等粒度绑定,一个状态对应某个组件,而不再是具体标签(细粒度绑定机制),当状态发生变化只通知到组件,组件内部通过VirtualDOM更新DOM标签。Vue通过变化侦测和VirtualDOM解决依赖追踪的开销问题。模板的作用是描述状态与DOM之间的映射关系,通过模板可以编译出一个渲染函数,执行这个渲染函数可以得到VirtualDOM中所提供的VNode。
getter中收集依赖,setter中触发依赖。
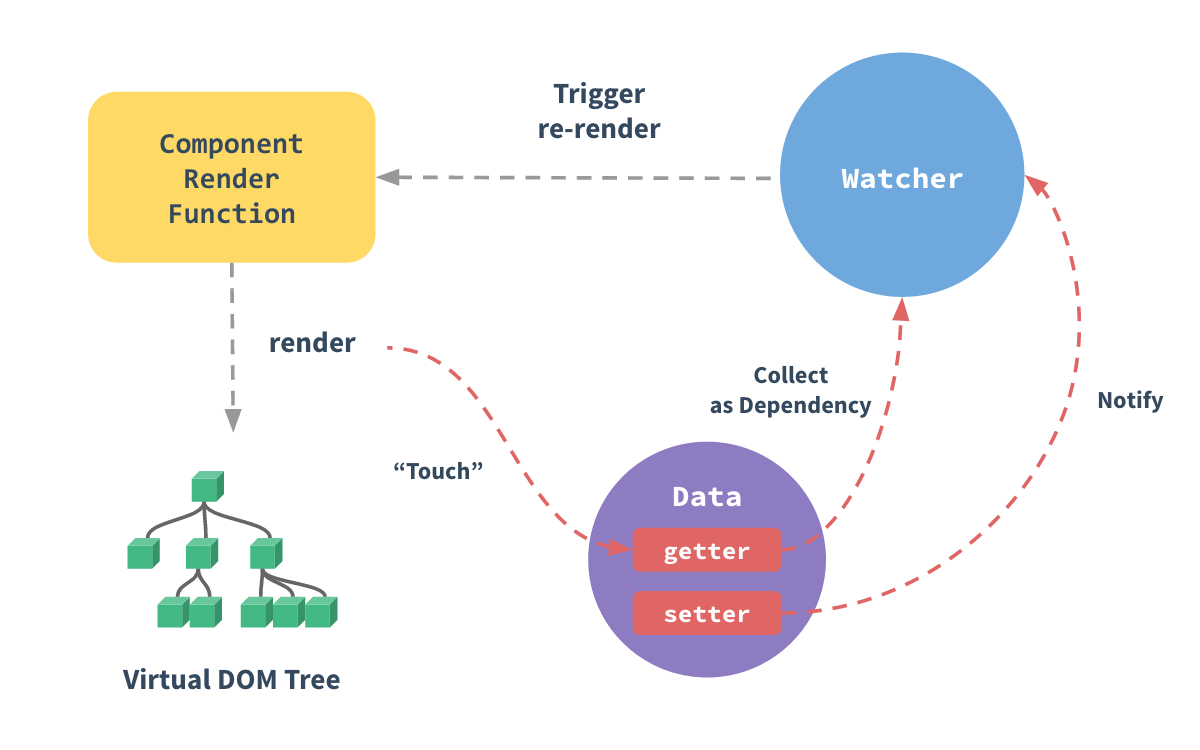
状态——>VNode(节点描述对象)——>DOM
diff的目的是渲染页面、创建新增的节点、删除已经废弃的节点。修改需要更新的节点。
更新节点(属性,内容)
oldVnode没有children?
空标签:将vnode中的children插入到DOM中
有文本:先清空文本,然后在将children插入到DOM中
oldVnode有children?
对children进行diff与更新
更新子节点四种操作:新增子节点、更新子节点、移动子节点、删除子节点
Web系统的经典架构图
采用token方式进行用户鉴权:
- 客户端(pc,移动端,平板等)首次登录,服务端签发
token,在token中放入用户信息(如userId)等返回给客户端 - 客户端访问服务端接口,需要在头部携带
token,跟表单一并提交到服务端 - 服务端在
web层统一解析token鉴权,同时取出用户信息(如userId)并继续向底层传递,传到服务层操作业务逻辑 - 服务端在
service层取到用户信息(如userId)后,执行相应的业务逻辑操作
- 浏览器发送请求
- 直接到达html页面(前端控制路由与渲染页面,整个项目开发的权重前移)
- html页面负责调用服务端接口产生数据(通过ajax等等,后台返回json格式数据,json数据格式因为简洁高效而取代xml)
- 填充html,展现动态效果,在页面上进行解析并操作DOM。
page object
pages offer :action,navigation,getter functionalities

state35和state39相同的导航web元素(例如,可以点击的链接)和两个不同的文本元素,而state44包含相同的导航web元素和动作(例如,可以填充的文本字段)。
代码量比较图

Selenium的等待
隐性等待:
1 | driver.implicitly_wait(30) # 隐性等待,最长等30秒 |
隐性等待是设置了一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一步。隐性等待对整个driver的周期都起作用,所以只要设置一次即可。
显性等待:
1 | try: |
最长的等待时间取决于两者之间的大者,此例中为20,如果隐性等待时间 > 显性等待时间,则该句代码的最长等待时间等于隐性等待时间。
WebDriverWait类是显性等待类,参数与方法。
1 | selenium.webdriver.support.wait.WebDriverWait(类) |
1 | WebDriverWait(driver, 超时时长, 调用频率, 忽略异常).until(可执行方法, 超时时返回的信息) |
expected_conditions
1 | selenium.webdriver.support.expected_conditions(模块) |
python tox
1 | bok-choy中的tox.ini |
conftest.py
1 | .. |
详细解释:
tox是通用的虚拟环境管理和测试命令行工具。tox能够让我们在同一个Host上自定义出多套相互独立且隔离的python环境(tox是openstack社区最基本的测试工具,比如python程序的兼容性、UT等)。它的目标是提供最先进的自动化打包、测试和发布功能。
- 作为持续集成服务器的前端,大大减少测试工作所需时间;
- 检查软件包能否在不同的python版本或解释器下正常安装;
- 在不同的环境中运行测试代码。
参考:
测试路径生成准则,用户会话的session获取:
导航图的组成:
G=<N,E>
po(n)->po(m):po(n)返回po(m)
边:n->m
n,m为结点
有向图的深度优先生成树:
有向图的特点:边的方向性导致即使两个顶点有边相连也不一定是可达的。树边(tree edges), 回退边(back edges),向前边(forward edges), 横边(cross edges)。其中后三者是树实际不存在的边。
事实上,有以下结论(其中num[]保存的是树节点的先序序列即DFS序列):
1、若num[v] < num[w],即v在w之前被访问,则(v,w)是树边或向前边;
1 | 此时,若visited[v]= true, visited[w] = false,(v,w)为 树边; |
2、若num[v] > num[w],即v在w之后被访问,故visited[v] = true则visited[w] = true,则(v,w)是回退边或横边;
1 | 当产生树边(i,j) 时,同时记下j的父节点:parent[j] = i, 于是对图中任一条边(v,w),由结点v沿着树边向上(parent中)查找w(可能直到根); |
测试路径生成规则:
规则1:将存在条件冲突的迁移放置在状态迁移树的不同分支上。
不可行路径:无法找到一个可以同时满足两条迁移条件的变量值,考虑到用户权限。
python动态获取对象的属性和方法
参考:动态获取对象的属性和方法
getattr(obj, attr):
调用这个方法将返回obj中名为attr值的属性的值,例如如果attr为’bar’,则返回obj.bar。
Testing SPA(Youtobe)
What are SPAs and why should you care about them?
- HTML+CSS+JS
- No Reloads
- Fluent,Interactive UX
- Build Once - Deploy Everywhere

- benefits of SPA
- Interactive
- Faster
- Economical
- Cheaper - thick clients
- No install
- Build once,run everywhere
Testing SPAs
- Manual testing is very similar to traditional web sites
- Mastering the browser console is a must
Automation with Selenium
- The DOM changes very often
- Requires A lot of dynamic waits or long global implicit waits
- will make your tests slow or fragile
- will make you tests harder to read and maintain

Implementation
- Requirements:
- Track app state
- Instrument each test step
when is the application Ready
wait for:
- AJAX(HTTP requests)
- Async code(setTimeout-s,WebWorkers,Animations)
Do not wait for:
- Reoccurring actions(setInterval-s)
Measuring Performance - What we need?
- Go through all the pages/states
- Measure how long does each one take
- find out where the time is spent - UI or server?
Crawling Problem
- Need to sync first,so that we know when everything is processed
- How to automatically find all the pages/places in the application and to navigate to them
- No tool can automatically do it reliable and completely
- Navigation is done via JS - understanding of business logic is required
- No uniform way of doing it
The solution - The Navigator Class
- A class that can navigate the application like a real user would
- Maintenance and update is very simple
- Automatic Synchronization
- Already had most of the code
- Allow for different scenarios/user journeys
Layout Testing - Responsiveness
Runs on a lot of different devices / resolutions
Image comparison - ImageMagick , GraphicsMagick,pdiff,Guiffy
Issues:
- Animations
- Different OS
- Manual verification
Securing a SPA
- Obfuscation -UglifyJS
- Administration code
- Static Code Analysis - JSHint,JSLint,ESLint
- Navigator + security tool(ZAP,Nessus,Burp,etc.)
- Automate what is not caught by you tool(XSS mostly)
Other uses of yhe navigator
SEO
Analytics
i10n & I10n
HTTPS/HTTP Mixed Content
PICT实验部分
就是转为ANSI格式
生成密钥:
powershell
ssh-keygen.exe -t rsa
addUserForm因子表
| Parameter | Value |
|---|---|
| name | |
| phone | |
| passwd | |
| gender_key | 男、女、未知 |
| level_key | 普通用户、VIP用户、高级VIP用户 |
| state_key | 可用、禁用、注销 |
| birthday |
正则表达式:
username:
1 | ^[\w\u4e00-\u9fa5]{6,20}(?<!_)$ |
phone:
1 | ^0\d{2,3}[- ]?\d{7,8} |
birthday:
1 | ^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$ |
Factory Boy
1 | import factory |
alert,浏览器弹出框,一般是用来确认某些操作、输入简单的text或用户名、密码等,根据浏览器的不同,弹出框的样式也不一样,不过都是很简单的一个小框。在firebug中是无法获取到该框的元素的,也就是说alert是不属于网页DOM树的。
window,浏览器窗口,点击一个链接之后可能会打开一个新的浏览器窗口,跟之前的窗口是平行关系(alert跟窗口是父子关系,或者叫从属关系,alert必须依托于某一个窗口),有自己的地址栏、最大化、最小化按钮等。这个很容易分辨。
div伪装对话框,是通过网页元素伪装成对话框,这种对话框一般比较花哨,内容比较多,而且跟浏览器一看就不是一套,在网页中用firebug能够获取到其的元素
1 | script = dedent(""" |
1 | self.browser.Firefox.maximize_window() |
上面代码可以使用selenium原生API
答:自动化测试用例的执行策略是要看自动化测试的目的,通常有如下几种策略:
一,自动化测试用例是用来监控的,在此目的下,我们就把自动化测试用例设置成定时执行的,如果每五分钟或是一个小时执行一次,在jenkins上创建一个定时任务即可。
二,必须回归的用例。有些儿测试用例,如BVT测试用例,我们在公司产品任何变动上线之前都需要回归执行。那我们就把测试用例设置成触发式执行,在jenkins上将我们的自动化测试任务绑定到开发的build任务上。当开发人员在仿真环境上部代码的时候,我们的自动化测试用例就会被触发执行。
三,不需要经常执行的测试用例。像全量测试用例,我们没有必要一直回归执行,必竟还是有时间消耗的,有些非主要业务线也不需要时时回归。这类测试用例我们就采用人工执行,在jenkins创建一个任务,需要执行的时候人工去构建即可。