selenium webdriver 和并行测试
本文恢复2018-10-09
python 用selenium做自动化测试[1]
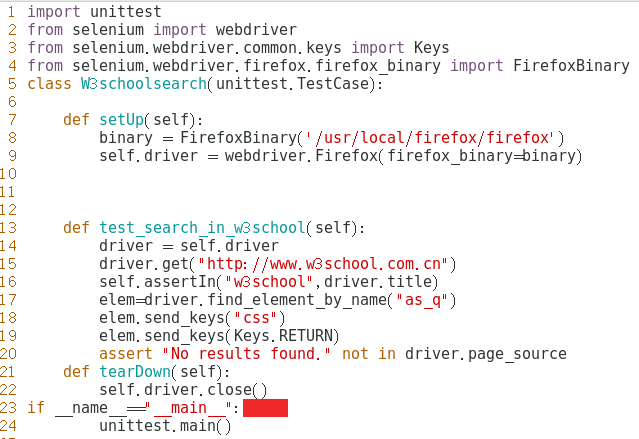
在w3school里搜索css
1 | python3 test_w3school_search.py |
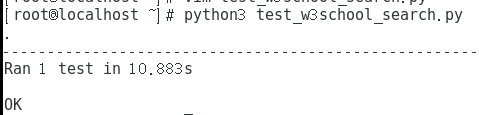
XPath路径表达式:
http://www.ruanyifeng.com/blog/2009/07/xpath_path_expressions.html阮一峰
1.基于Python的Selenium自动化测试
练习实例,把官方教程中能实现的方法都实现一下(在上面的案例中进行更改)
直接执行:直接用unittest.main() 执行,这里它搜索所有以test开头的测试用例方法,按照ASCII的顺序执行多个用例。
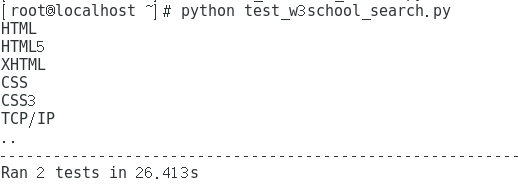
与页面交互(输出W3School中HTML教程中的相关列表文本)
因为我没有用到测试套件,所以测试的时候打开了两次浏览器,但其实在第一次打开浏览器的时候就已经看到了输出,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13class W3schoollist(unittest.TestCase):
26 def setUp(self):
27 binary=FirefoxBinary('/usr/local/firefox/firefox')
28 self.driver=webdriver.Firefox(firefox_binary=binary)
29 def test_list_in_w3school(self):
30 driver=self.driver
31 driver.get("http://www.w3school.com.cn")
#google开发者工具里面可以直接copy XPath.
32 elems=driver.find_elements_by_xpath("//*[@id='navsecond']/ul[1]/li")
33 for ele in elems:
34 print ele.text
35 def tearDown(self):
36 self.driver.close()
- 选择下拉列表,处理
SELECT元素 - 控制浏览器前进后退:
1 | 1 from selenium import webdriver |
- qq邮箱登录:
一直定位不到元素,最后看了这篇博客解决:
https://blog.csdn.net/otianye/article/details/78203435
需要先通过定位frame然后再定位frame里边的某一个元素的方法定位此元素
1 | 1 from selenium import webdriver |
- submit()方法用于提交表单
1 | 1 from selenium import webdriver |
- 鼠标事件(将关于鼠标操作方法封装在ActionChains类内提供)
1 | 1 from selenium import webdriver |
- 获得验证信息(以qq邮箱登录为例)
2.Selenium和unittest结合
3.Test Suites
参考:https://blog.csdn.net/u011436666/article/details/73473013
用测试套件的形式组织一下测试(就使用与页面交互的案例中的两个测试用例):
1 | 1 import unittest |
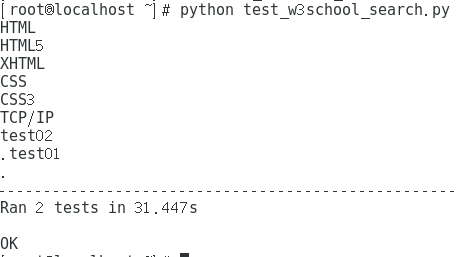
可以看到运行的两个测试是按照我调用的顺序来的,test2->test1
4.Selenium-grid
Selenium-Grid可以测试集分布在多个环境中并行运行测试用例。这有两个好处。 首先,如果你有一个大的测试集或者一个运行缓慢的测试集,你可以通过使用Selenium Grid来划分你的测试集,同时使用这些不同的机器来运行不同的测试。另外,如果您必须在多个环境中运行测试套件,您可以让不同的远程机器同时支持并运行您的测试。 在每种情况下,Selenium Grid通过使用并行处理大大缩短了运行套件所需的时间。
这个的使用后期研究后会再总结~
5.美化报告样式和发送结果邮件:
参考:https://blog.csdn.net/u011436666/article/details/73473013
1 | 1 import unittest |
将HTMLTestRunner.py移入python安装目录(仅支持python2,网上有教程可以修改到支持py3):
1 | mv HTMLTestRunner.py /usr/lib/python2.7/site-packages/ |
注意:密码是qq邮箱第三方授权码!!!,如果你使用自己的密码则会报错:
1 | smtplib.SMTPAuthenticationError: (535, 'Error: \xc7\xeb\xca\xb9\xd3\xc3\xca\xda\xc8\xa8\xc2\xeb\xb5\xc7\xc2\xbc\xa1\xa3\xcf\xea\xc7\xe9\xc7\xeb\xbf\xb4: http://service.mail.qq.com/cgi-bin/help?subtype=1&&id=28&&no=1001256') |

运行 GNOME
python用selenium做自动化测试[2]
- checkbox实践
测试对象网址
代码先贴上:
1 | 1 from selenium import webdriver |
刚开始遇到一个报错:
1 | selenium.common.exceptions.WebDriverException: Message: Process unexpectedly closed with status: 1 |
最后发现原因是用非root用户进入了。
- 多窗口切换
1 | 1 #!/usr/bin/python3.6 |
- 上传文件
虫师书中是对windows控件的操作部分,故不做实验
- 下载文件
1 | 1 #!/usr/bin/python3.6 |
代码就是这样,but网速太渣没出结果
- 调用JS
1 | 1 #!/usr/bin/python3.6 |
- 验证码处理
1 |
模块化驱动测试实例:
线性:
1 | 1 from selenium import webdriver |
模块化:
1 | #登录与退出 public.py |
1 | 主文件 mailTest.py |
数据驱动测试(参数化)
1 | 1 #-*- coding:utf-8 -*- |
1 | 1 #-*- coding:utf-8 -*- |
unittest自动识别测试用例并执行
测试用例:
1 | #calculator.py |
1 | #testadd.py |
1 | #testsub.py |
1 | #runtest.py |
1 | [root@localhost unittestcase]# python runtest.py |
Python并行
在python中,线程共享相同的地址空间和内存,所以线程之间的通信比较容易。
进程之间的通信方式有:管道,消息队列,Socket接口(TCP/IP)等
进程间的同步使用锁,这一点和线程是一样的。并且Python还提供了进程池Pool对象,可以方便的管理和控制线程
Python下有许多开源的框架来支持分布式的并发,提供有效的管理手段包括:
Celery是一个非常成熟的Python分布式框架,可以在分布式的系统中,异步的执行任务,并提供有效的管理和调度功能。参考这里
另外,许多的分布式系统多提供了对Python接口的支持,例如Spark
伪线程 (Pseudo-Thread)
看上去像是线程,使用的接口类似线程接口,但是实际使用非线程的方式,对应的线程开销也不存的。
greenlet 使用伪线程,我们可以有效的控制程序的执行流程,但是伪线程并不存在真正意义上的并发。
concurence https://github.com/concurrence/concurrence
通常需要用到并发的场合有两种,一种是计算密集型,也就是说你的程序需要大量的CPU资源;另一种是IO密集型,程序可能有大量的读写操作,包括读写文件,收发网络请求等等。
多进程 multiprocess
理论上对于计算密集型的任务,使用多进程并发比较合适,在以下的例子中,进程池的规模设置为5,修改进程池的大小可以看到对结果的影响,当进程池设置为1时,和多线程的结果所需的时间类似,因为这时候并不存在并发;当设置为2时,响应时间有了明显的改进,是之前没有并发的一半;
1 | from multiprocessing import Pool |
IO密集型的任务是另一种常见的用例,例如网络WEB服务器就是一个例子,每秒钟能处理多少个请求时WEB服务器的重要指标。
对于IO密集型的任务,使用多线程,或者是多进程都可以有效的提高程序的效率,而使用伪线程性能提升非常显著,eventlet比没有并发的情况下,响应时间从9秒提高到0.03秒。同时eventlet/gevent提供了非阻塞的异步调用模式,非常方便。这里推荐使用线程或者伪线程,因为在响应时间类似的情况下,线程和伪线程消耗的资源更少。
内存架构
共享内存和分布式内存的区别:
共享内存能够在内存中构建数据结构并在子进程间通过引用直接访问该数据结构。而对于分布式内存系统来说,必须在每个局部内存保存共享数据的副本。一个处理器会向其他处理器发送含有共享数据的消息从而创建数据副本。
并行编程模型
共享内存模型:
在这个编程模型中所有任务都共享一个内存空间,对共享资源的读写是 异步的。系统提供一些机制,如锁和信号量,来让程序员控制共享内存的访问权限。使用这个编程模型的优点是,程序员不需要清楚任务之间通讯的细节。但性能方面的一个重要缺点是,了解和管理数据区域变得更加困难;将数据保存在处理器本地才可以节省内存访问,缓存刷新以及多处理器使用相同数据时发生的总线流量。
多线程模型:
在这个模型中,单个处理器可以有多个执行流程,例如,创建了一个顺序执行任务之后,会创建一系列可以并行执行的任务。通常情况下,这类模型会应用在共享内存架构中。由于多个线程会对共享内存进行操作,所以进行线程间的同步控制是很重要的,作为程序员必须防止多个线程同时修改相同的内存单元。现代的CPU可以在软件和硬件上实现多线程。POSIX 线程就是典型的在软件层面上实现多线程的例子。Intel 的超线程 (Hyper-threading) 技术则在硬件层面上实现多线程,超线程技术是通过当一个线程在停止或等待I/O状态时切换到另外一个线程实现的。使用这个模型即使是非线性的数据对齐也能实现并行性。
消息传递模型:
消息传递模型通常在分布式内存系统(每一个处理器都有独立的内存空间)中应用。更多的任务可以驻留在一台或多台物理机器上。程序员需要确定并行和通过消息产生的数据交换。实现这个数据模型需要在代码中调用特定的库。于是便出现了大量消息传递模型的实现,最早的实现可以追溯到20世纪80年代,但直到90年代中期才有标准化的模型——实现了名为MPI (the Message Passing Interface, 消息传递接口)的事实标准。MPI 模型是专门为分布式内存设计的,但作为一个并行编程模型,也可以在共享内存机器上跨平台使用。
数据并行模型:
在这个模型中,有多个任务需要操作同一个数据结构,但每一个任务操作的是数据的不同部分。在共享内存架构中,所有任务都通过共享内存来访问数据;在分布式内存架构中则会将数据分割并且保存到每个任务的局部内存中。为了实现这个模型,程序员必须指定数据的分配方式和对齐方式。现代的GPU在数据已对齐的情况下运行的效率非常高。
设计并行程序:
- 任务分解 (Task decomposition)
- 任务分配 (Task assignment)
- 聚合 (Agglomeration)
- 映射 (Mapping)
基于线程的并行
RLock()的概念:
RLock其实叫做“Reentrant Lock”,就是可以重复进入的锁,也叫做“递归锁”。这种锁对比Lock有是三个特点:
- 谁拿到谁释放。如果线程A拿到锁,线程B无法释放这个锁,只有A可以释放;
- 同一线程可以多次拿到该锁,即可以acquire多次;
- acquire多少次就必须release多少次,只有最后一次release才能改变RLock的状态为unlocked)
信号量是一个内部数据,用于标明当前的共享资源可以有多少并发读取。
信号量的操作有两个函数,即 acquire() 和 release()
- 每当线程想要读取关联了信号量的共享资源时,必须调用
acquire(),此操作减少信号量的内部变量, 如果此变量的值非负,那么分配该资源的权限。如果是负值,那么线程被挂起,直到有其他的线程释放资源。 - 当线程不再需要该共享资源,必须通过
release()释放。这样,信号量的内部变量增加,在信号量等待队列中排在最前面的线程会拿到共享资源的权限。
使用 with 语法可以在特定的地方分配和释放资源,因此, with 语法也叫做“上下文管理器”。在threading模块中,所有带有 acquire() 方法和 release() 方法的对象都可以使用上下文管理器。
logging模块是线程安全的
上下文管理器with的用法:
https://www.kawabangga.com/posts/2010
GIL是CPython解释器引入的锁,GIL在解释器层面阻止了真正的并行运行。解释器在执行任何线程之前,必须等待当前正在运行的线程释放GIL。事实上,解释器会强迫想要运行的线程必须拿到GIL才能访问解释器的任何资源,例如栈或Python对象等。这也正是GIL的目的——阻止不同的线程并发访问Python对象。这样GIL可以保护解释器的内存,让垃圾回收工作正常。但事实上,这却造成了程序员无法通过并行执行多线程来提高程序的性能。如果我们去掉CPython的GIL,就可以让多线程真正并行执行。GIL并没有影响多处理器并行的线程,只是限制了一个解释器只能有一个线程在运行。
增加线程并不会提高应用启动的时间,但是可以支持并发。例如,一次性创建一个线程池,并重用worker会很有用。这可以让我们切分一个大的数据集,用同样的函数处理不同的部分(生产者消费者模型)。
基于进程的并行
multiprocessing 是Python标准库中的模块,实现了共享内存机制,也就是说,可以让运行在不同处理器核心的进程能读取共享内存。
mpi4py 库实现了消息传递的编程范例(设计模式)。简单来说,就是进程之间不靠任何共享信息来进行通讯(也叫做shared nothing),所有的交流都通过传递信息代替。
官网对于multiprocessing的相关:
https://docs.python.org/3.3/library/multiprocessing.html
创建进程:
1 | # -*- coding: utf-8 -*- |
执行:
1 | python spawn_a_process.py |
在后台运行一个进程:
1 | background_process = multiprocessing.Process(name='background_process', target=foo) |
后台进程不允许创建子进程。否则,当后台进程跟随父进程退出的时候,子进程会变成孤儿进程。另外,它们并不是Unix的守护进程或服务(daemons or services),所以当非后台进程退出,它们会被终结。
我们通过读进程的 ExitCode 状态码(status code)验证进程已经结束, ExitCode 可能的值如下:
- == 0: 没有错误正常退出
- > 0: 进程有错误,并以此状态码退出
- < 0: 进程被
-1 *的信号杀死并以此作为 ExitCode 退出
进程的同步原语如下:
- Lock: 这个对象可以有两种装填:锁住的(locked)和没锁住的(unlocked)。一个Lock对象有两个方法,
acquire()和release(),来控制共享数据的读写权限。 - Event: 实现了进程间的简单通讯,一个进程发事件的信号,另一个进程等待事件的信号。
Event对象有两个方法,set()和clear(),来管理自己内部的变量。 - Condition: 此对象用来同步部分工作流程,在并行的进程中,有两个基本的方法:
wait()用来等待进程,notify_all()用来通知所有等待此条件的进程。 - Semaphore: 用来共享资源,例如,支持固定数量的共享连接。
- Rlock: 递归锁对象。其用途和方法同
Threading模块一样。 - Barrier: 将程序分成几个阶段,适用于有些进程必须在某些特定进程之后执行。处于障碍(Barrier)之后的代码不能同处于障碍之前的代码并行。
进程池(Pool):
apply(): 直到得到结果之前一直阻塞。apply_async(): 这是apply()方法的一个变体,返回的是一个result对象。这是一个异步的操作,在所有的子类执行之前不会锁住主进程。map(): 这是内置的map()函数的并行版本。在得到结果之前一直阻塞,此方法将可迭代的数据的每一个元素作为进程池的一个任务来执行。map_async(): 这是map()方法的一个变体,返回一个result对象。如果指定了回调函数,回调函数应该是callable的,并且只接受一个参数。当result准备好时会自动调用回调函数(除非调用失败)。回调函数应该立即完成,否则,持有result的进程将被阻塞。pool.map()方法的记过和Python内置的map()结果是相同的,不同的是pool.map()是通过多个并行进程计算的。
异步模型
任务(不同的颜色表示不同的任务)可能被其他任务插入,但是都处在同一个线程下。
异步模型与多线程编程模型很大的一点不同是, 多线程由操作系统决定在时间线上什么时候挂起某个活动或恢复某个活动,而在异步并发模型中,程序员必须假设线程可能在任何时间被挂起和替换。
当一个程序变得很大而且复杂时,将其划分为子程序,每一部分实现特定的任务是个不错的方案。子程序不能单独执行,只能在主程序的请求下执行,主程序负责协调使用各个子程序。协程就是子程序的泛化。和子程序一样的事,协程只负责计算任务的一步;和子程序不一样的是,协程没有主程序来进行调度。这是因为协程通过管道连接在一起,没有监视函数负责顺序调用它们。
yield表示协程在此暂停,并且将执行权交给其他协程。因为协程可以将值与控制权一起传递给另一个协程,所以“yield一个值”就表示将值传给下一个执行的协程。
使用Asyncio控制任务
在同一事件循环中,运行某一个任务的同时可以并发地运行多个任务。当协程被包在任务中,它会自动将任务和事件循环连接起来,当事件循环启动的时候,任务自动运行。这样就提供了一个可以自动驱动协程的机制。