基于搜索的测试工具Evosuite-内附学习详细过程
Macos10.14 Idea maven
Evosuite用maven构建
【参考来源】http://www.evosuite.org/documentation/tutorial-part-2/
!如果在照着做出现找不到文件的情况,请翻到本文最后看最终的pom.xml配置以及文件结构
pom.xml
1 | <?xml version="1.0" encoding="UTF-8"?> |
The EvoSuite Maven plugin命令简介
1)generate
这用于通过EvoSuite生成测试用例。 将为所有子模块中的所有类生成测试。 您需要确保代码已编译。
1 | mvn compile evosuite:generate |
可以跟的参数
memoryInMB:EvoSuite允许分配的总兆字节数(默认为800)
cores:EvoSuite可以使用的CPU内核总数(默认为1)
timeInMinutesPerClass:EvoSuite可以花多少分钟为每个类生成测试(默认2)
2)info:提供到目前为止所有已生成测试的信息
3)export: 默认情况下,EvoSuite在“ .evosuite”文件夹中创建测试。 通过使用“导出”,将生成的测试复制到另一个文件夹,该文件夹可以使用“ targetFolder”选项设置(默认值为“ src / test / java”)。
如果不使用“ mvn evosuite:export”将测试导出到“ src / test / java”,则“ mvn test”之类的命令将不会执行这些测试,因为它们的源代码不在构建路径中。 您可以使用“ build-helper-maven-plugin”插件添加自定义源文件夹.
4)clean:删除“ .evosuite”文件夹中的所有数据,该文件夹用于存储到目前为止生成的所有最佳测试.
5)prepare:需要同时运行EvoSuite测试和现有测试.
1 | mvn evosuite:prepare test |
最好仅将evosuite插件配置为始终运行,如前所述。
eg.
1 | mvn -DmemoryInMB=2000 -Dcores=2 evosuite:generate evosuite:export test |
这将使用2个内核和2GB内存为所有类生成测试,将生成的测试复制到“ src / test / java”,然后执行它们。 注意:如果项目已经进行了一些测试,那么这些测试将作为常规“测试”阶段的一部分执行。
maven集成
准备被测项目
下载被测项目
1 | wget http://evosuite.org/files/tutorial/Tutorial_Maven.zip |
和以前一样,我们可以使用以下命令来编译项目中的类
1 | mvn compile |
目录如下
然后这个项目本身有测试,位于JdbcDemo/src/test/java/StackTest.java
这个属于已有测试,可以使用命令
1 | mvn test |
更近一步看pom.xml
如果您已经非常熟悉Maven,那么本节可能不会告诉您任何新内容。 但是,了解如何配置Maven项目以配置项目以使用EvoSuite至关重要。 因此,我们现在将仔细研究示例项目的主要Maven配置文件,即文件pom.xml。
我们的示例项目中的pom.xml基于使用mvn archetype:generate生成的基本版本。 它从有关该项目的一些基本元信息开始
查看help命令
1 | mvn evosuite:help |
1 | [INFO] Maven Plugin for EvoSuite 1.0.6 |
我们可以使用-Dproperty = value语法为插件目标设置属性,就像为任何Java进程设置属性一样。 例如,要获取有关在执行帮助插件目标时生成插件目标的更多详细信息,我们可以运行以下命令
1 | mvn evosuite:help -Ddetail=true -Dgoal=generate |
如果运行此命令,应该会看到可以为生成插件目标设置的所有属性的列表。这个是显示generate参数
1 | evosuite:generate |
现在让我们使用evosuite生成些测试
1 | mvn evosuite:generate |
1 | [INFO] * EvoSuite 1.0.6 |
我的电脑烫的。。。,让我们来看看这个优秀的工具生成的测试用例,生成的没有成功导出到src/main/test/java,暂时先在目录~/IdeaProjects/JdbcDemo/.evosuite/best-tests下看
为了对比人工和自动生成的,我们就看一下Stack的测试类ba
1 | /* |
手工测试类只有一个判断栈空操作。假设您对这些测试套件感到满意,我们可以将它们集成到源代码树中。 默认情况下,JUnit测试应该位于Maven项目的src / test / java中,因此EvoSuite将在其中放置测试套件。 为此,请调用以下命令
1 | mvn evosuite:export |
现在,您应该将测试套件复制到src / test / java-确保它们在那里
o天,我文件路径写错了。。。。我就说,既然已经产生了测试,那就先注释掉pom文件,开始导出

执行evosuite产生的测试
现在我们在源代码树中有了这些测试,执行它们将是很棒的。 使用Maven,可以通过调用测试生命周期阶段来完成
1 | mvn test |
jdbc那部分测试报错先不看,先看官方那个例子

请注意,测试的数量不可避免地会有所不同– EvoSuite使用随机算法生成测试,因此每次调用它时,您都会得到不同的结果。
将EvoSuite测试与开发人员编写的测试分开
当我们使用mvn evosuite:export导出测试时,它们被复制到src / test / java中,这是Maven希望所有测试都在的位置。 有时,开发人员可能更愿意将自己的测试与生成的测试分开。
假设我们不希望在src / test / java中生成测试。 删除我们已经在那里导出的测试
1 | ~/IdeaProjects/JdbcDemo » rm -r src/test/java/jdbc src/test/java/Tutorial_Maven |
导出目标提供了一个属性,用于指定将测试导出到的位置–回想一下,我们可以使用以下命令来获取有关此目标的详细信息,有两种方式可以导出到指定位置
1 | mvn evosuite:export -DtargetFolder=src/test/evosuite |
或者在pom中配置
1 | <properties> |
与开发人员书写测试一起执行EvoSuite测试
为了确保该工具仅对EvoSuite测试有效,我们需要为EvoSuite测试添加初始化侦听器。 为此,将以下部分添加到pom.xml文件的<build>部分的<plugins>部分中
1 | <plugin> |
运行实验
【参考来源】http://www.evosuite.org/documentation/tutorial-part-3/
收集有关测试生成结果的数据
选择输出变量进行数据收集
生成数据的基本分析
使用EvoSuite运行大型实验
实验前准备-当然是下载官方提供的项目咯
对于本教程的第三部分,我们将研究如何收集有关测试生成的数据,这是在测试生成上运行实验时通常需要的。 我们将使用一个简单的示例场景:默认情况下,EvoSuite使用不同覆盖标准的组合。 与仅将分支覆盖范围用作目标条件相比,这种组合有什么影响? 一个合理的假设是,这种组合会导致更多的测试和更好的测试套件。 但这是真的吗? 让我们做一些实验来找出答案!
实验将涉及在多个类中使用其默认配置运行EvoSuite,并将其配置为仅使用分支覆盖率,然后对所得测试套件进行不同的测量。 在进行此类实验时,类别的选择会影响我们得出的结论的概括程度:如果我们使用非常具体且很小的类别选择,那么无论我们的发现如何,它们可能仅与特定类型的类别相关。 因此,我们通常希望选择尽可能多的,尽可能多样的并且具有代表性的类,以便获得概括的结果。
1 | wget http://evosuite.org/files/tutorial/Tutorial_Experiments.zip |
此命令下载所有依赖项jar文件,并将它们放入target / dependency目录。 使用-DincludeScope = runtime将范围指定为运行时的原因是,该项目具有对JUnit和EvoSuite的测试依赖关系-但是这些依赖关系都不是为了为被测类生成一些测试所必需的,我们只需要 编译和运行时依赖项。因此,完整的项目类路径由target / classes中的类和jar文件target / dependency / commons-collections-3.2.2.jar组成。 要创建保存此类路径的evosuite.properties文件,请使用以下命令:
1 | EVOSUITE -setup target/classes target/dependency/commons-collections-3.2.2.jar |
然后在evosuite.properties文件内的顶部指定路径
1 | CP=target/classes:target/dependency/commons-collections-3.2.2.jar |
首先下载jar包,地址http://www.evosuite.org/downloads/
1 | java -jar evosuite-1.0.6.jar -setup target/classes target/dependency/commons-collections-3.2.2.jar |

使用Evosuite收集数据
一定要记住更改POM文件后,要导入依赖
1 | mvn dependency:copy-dependencies -DincludeScope=runtime |
然后编译
1 | mvn compile |
1 | ~/IdeaProjects/JdbcDemo » java -jar evosuite-1.0.6.jar -class Tutorial_Experiments.Person zhengjiani@zhengjianideMacBook-Pro |
查看文件evosuite-report/statistics.csv
该文件为逗号分隔值格式。 第一行包含显示各个列所包含内容的标题,然后各行包含实际数据。 第一列包含我们测试的类的名称(tutorial.Person)。 第二列向我们显示了我们使用的覆盖标准–在这种情况下,我们将看到EvoSuite默认使用的标准的完整列表,以分号分隔。 第三列告诉我们已实现的覆盖率–在这种情况下为1.0,这意味着我们有100%的覆盖率(是的!),这是根据覆盖率目标与总目标的比率计算得出的(最后两列)。
1 | TARGET_CLASS,criterion,Coverage,Total_Goals,Covered_Goals |
让我们再测试一些类,使用分支覆盖率
1 | ~/IdeaProjects/JdbcDemo » java -jar evosuite-1.0.6.jar -class Tutorial_Experiments.Person -criterion branch zhengjiani@zhengjianideMacBook-Pro |
然后evosuite-report/statistics.csv文件更新
1 | TARGET_CLASS,criterion,Coverage,Total_Goals,Covered_Goals |
设置输出变量
我们可以生成的数据不仅仅是数据文件到目前为止向我们显示的列。 EvoSuite具有属性output_variables,该属性确定应将哪些值写入statistics.csv文件。在做这件事之前先删除旧的.csv文件。
1 | rm evosuite-report/statistics.csv |
输出变量主要有两种类型1)运行时变量,即为计算的结果(coverage)。2)而属性是我们可以设置的输入属性。 例如,TARGET_CRITERION和coverage是属性,而Total_Goals和Covered_Goals是运行时变量。
总而言之,对于我们的实验,我们希望获得以下数据
Class under test (TARGET_CLASS)
- Criteria (criterion) 覆盖准则
- Size (Size) 规模
- Length (Length) 语句长度
- Mutation score (MutationScore) 变异评分
变量列表以逗号分隔的形式传递给output_varibles属性。 让我们尝试一下
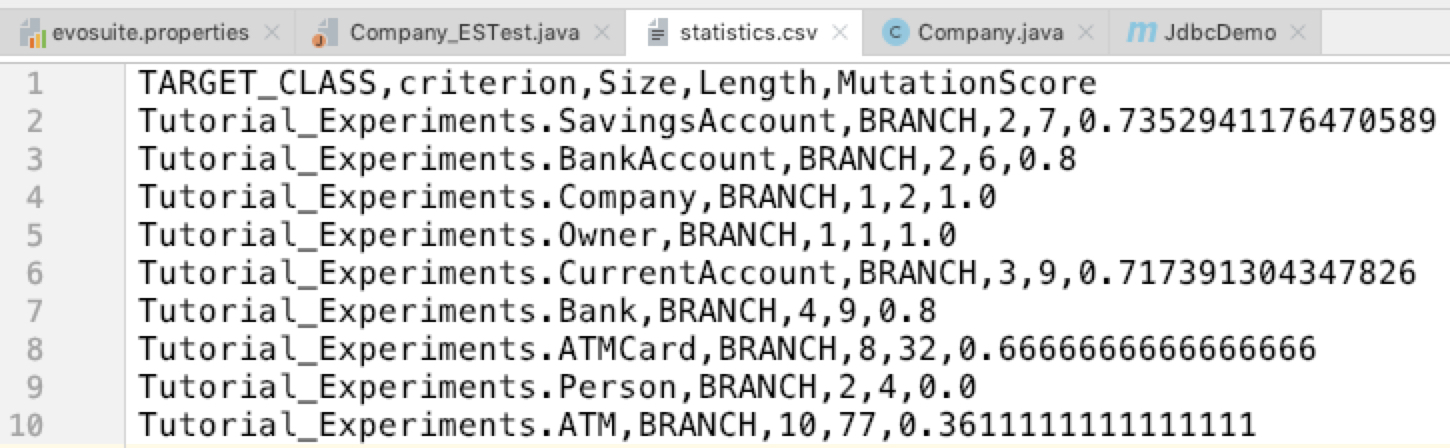
1 | ~/IdeaProjects/JdbcDemo » java -jar evosuite-1.0.6.jar -class Tutorial_Experiments.Company -criterion branch -Doutput_variables=TARGET_CLASS,criterion,Size,Length,MutationScore |

因此,我们刚刚生成了一个包含两个语句的测试,该测试杀死了为EvoSuite该类生成的所有突变体。
请注意,该断言不包括在EvoSuite的语句计数中。 这是因为断言不是作为基于搜索的测试生成的一部分而生成的,而是在后处理步骤中添加的。

运行一个实验
EvoSuite是随机的:如果连续运行两次,您将获得不同的结果。 这也意味着,如果您在一次运行中得到一个非常大的测试套件,那么在下一轮中您可能会获得一个具有不同大小的测试套件。 通常,当我们使用随机算法时,我们需要进行重复操作,并对统计数据进行统计分析。 因此,我们将对所有类进行测试,并重复10次。 此外,我们需要重复两次,一次仅使用分支覆盖,一次使用默认条件。
在开始实验前,还是要删除旧的.csv文件
使用-prefix表示测试包前缀,我实验无效。。。
1 | ~/IdeaProjects/JdbcDemo » java -jar evosuite-1.0.6.jar -criterion branch -prefix Tutorial_ -Doutput_variables=TARGET_CLASS,criterion,Size,Length,MutationScore |
我们可以使用-Dconfiguration_id = <name>语法告诉EvoSuite为正在运行的特定配置添加名称,然后将该属性包含在输出变量中。 因此,要运行实验,我们需要以下两个命令,一个用于分支覆盖,一个用于默认组合
1 | ~/IdeaProjects/JdbcDemo » java -jar evosuite-1.0.6.jar -criterion branch -prefix Tutorial_Experiments -Doutput_variables=TARGET_CLASS,criterion,Size,Length,MutationScore |
现在输出中有configuration_id了
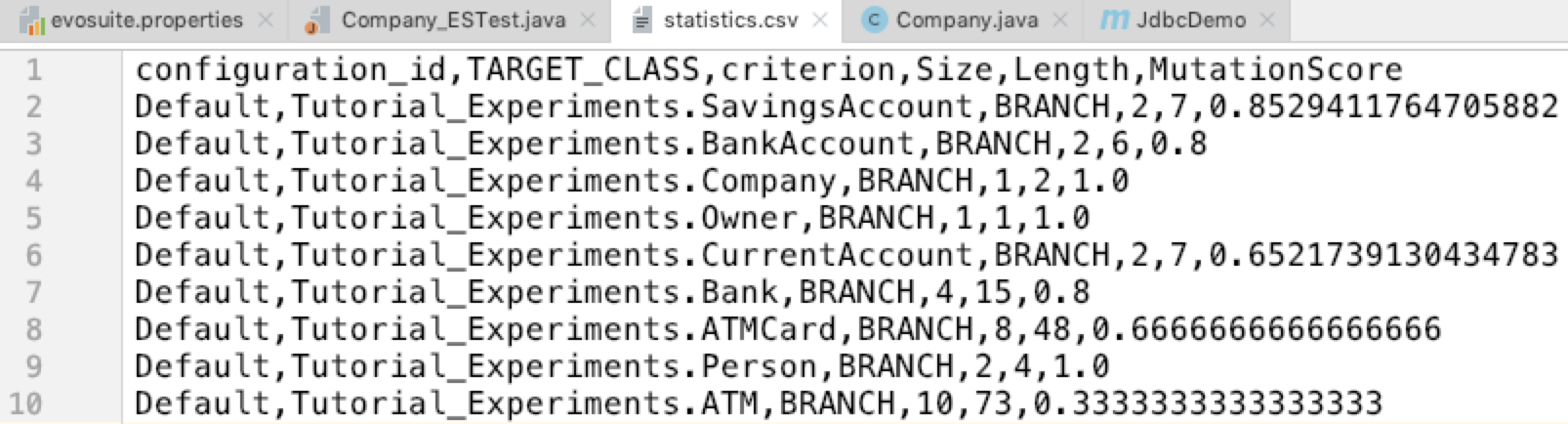
我们需要确定的不是在一种特定的运行中一种配置是否优于另一种配置,而是平均而言。 因此,我们需要重复几次实验,并做一些更严格的分析。
一种简单的重复方法是将调用简单地包装在bash循环中以运行它,例如5次
1 | ~/IdeaProjects/JdbcDemo » for I in {1..5}; do java -jar evosuite-1.0.6.jar -Dconfiguration_id=Branch -criterion branch -prefix Tutorial_Experiments -Doutput_variables=TARGET_CLASS,criterion,Size,Length,MutationScore ; done |
后期还是用脚本写吧。。。在控制台里太造孽了
这将需要一段时间。 实际上,对于严肃的实验而言,重复5次甚至不是一个合适的数目,理想情况下,您希望重复30次或更多次才能获得代表性的结果。 稍后我们将讨论如何进行较大的实验。
您可能会注意到分支覆盖范围的运行速度更快–这是因为EvoSuite一旦达到100%的分支覆盖范围,就会停止生成测试。 默认配置将包括一些不可行的测试目标,即没有测试的测试目标,在这种情况下,EvoSuite将尝试生成测试,直到用尽整个时间预算。
第一行命令的执行结果
1 | TARGET_CLASS,criterion,Size,Length,MutationScore |
第二行命令的执行结果
1 | configuration_id,TARGET_CLASS,criterion,Size,Length,MutationScore |
分析结果
1 | easy_install numpy |
上面结果太乱,我们用python写个脚本来分析一下,脚本应该和statistics.csv文件放在一起并且命名为analy-data.py
1 | #!/usr/bin/python |
最后一条命令(plt.show())将使用matplotlib打开三个图的三个窗口。在所有图中,我们可以清楚地看到,分支覆盖范围平均产生的测试更少,语句更少,并且这些测试的突变得分更低。
执行python3 analy-data.py
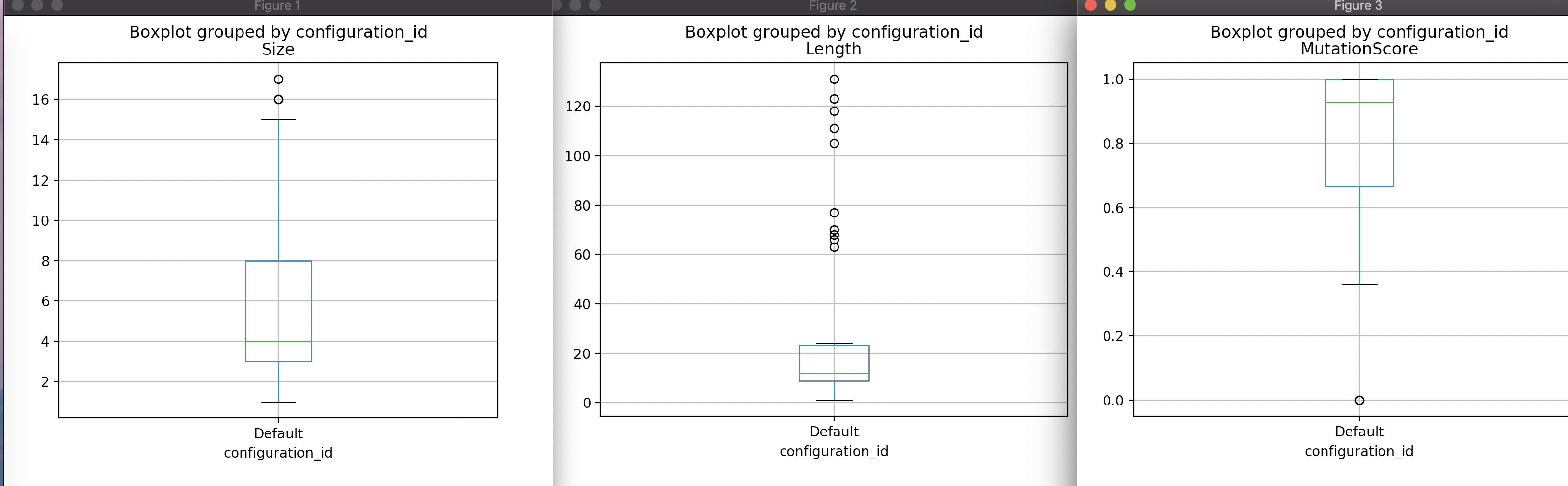
尽管在箱图中可以看到这种差异,但是在科学的背景下,最好还是使用统计分析来证明这种差异。特别是,我们通常希望量化效果的大小,并且希望量化对差异的信心。对于这些值中的第一个,可以使用不同的效果大小测量。让我们使用[Cohen’s-d(https://en.wikiversity.org/wiki/Cohen%27s_d)],它是[-1,1]范围内的值。为了量化我们对结果的信心,我们将使用众所周知的[p值(https://en.wikipedia.org/wiki/P-value)],这是观察到的结果无效的可能性我们实际测试的内容。要计算p值,我们需要选择适当的统计检验。让我们使用Wilcoxon等级检验,但统计检验的选择实际上超出了本教程。幸运的是,统计测试可以作为SciPy的一部分使用,因此请确保已安装.
1 | pip install scipy |
我们执行统计测试所需要做的就是创建值数组,并将其作为参数传递给scipy.stats.wilcoxon函数,该函数随后将为我们提供p值。 通常,小于0.05的p值被视为具有统计意义的结果的证据,因此这就是我们所希望的。
为了产生用于统计检验的输入数组,我们可以再次使用pandas库; 我们只需要选择数据的子集。 例如,要选择属于默认配置的所有数据,我们将使用df [df [‘configuration_id] ==’Default’]过滤数据集。 在结果数据中,我们可以选择列,例如 尺寸。 要计算Cohen的d,我们只需从Stackoverflow中提取一个片段:
1 | #!/usr/bin/python |
这个代码我运行后报错。。。有知道的小伙伴可以告诉我。。。
1 | ~/IdeaProjects/JdbcDemo/evosuite-report » python3 analy-data1.py zhengjiani@zhengjianideMacBook-Pro |
其他有用的变量【这个实验我没有做,感兴趣的可以看哈】
要获得可用输出变量的完整概述,当前最好的地方是源代码,尤其是文件[RuntimeVariable.java(https://github.com/EvoSuite/evosuite/blob/master/client/src/main/java/org/evosuite/statistics/RuntimeVariable.java)]。
例如,如果您想知道某些值随时间变化的方式,可以使用时间轴变量为您捕获这些数据。 假设我们想了解分支覆盖范围在搜索的前30秒如何演变,并且我们想每秒采样一次。 为此,我们将添加一个输出变量“ CoverageTimeline”,并使用-Dtimeline_interval = 1000指定采样间隔:
当我们指定总共30秒的时间预算(-Dsearch_budget = 30)时,statistics.csv文件现在将具有30列标记为CoverageTimeline_T1的列,直到CoverageTimeline_T30,并分别显示搜索的每一秒的值。
再举一个有趣的例子,BranchCoverageBitString变量将产生一个字符串“ 0”和“ 1”,其中每个数字代表程序中的一个分支,而1则表示该分支已被覆盖。 该位串使我们能够比较特定分支是否被特定配置覆盖。
运行大型实验《并行化》
运行大型实验时,EvoSuite在命令行上显示的进度条将浪费日志文件中的空间。通过添加-Dshow_progress = false禁用它。
当并行运行多个EvoSuite作业时,请确保它们不要尝试写入同一evosuite-report / statistics.csv,因为同时访问会破坏该文件。而是使用属性-Dreport_dir = <目录>为不同的作业设置不同的目录。实验完成后,您将需要再次将单个结果文件聚合到一个大数据文件中。
扩展EvoSuite(以下大部分内容为翻译)
主要从下面4个方面扩展
- Building EvoSuite
- Modifying the search algorithm 改变搜索算法
- Adding new fitness functions 增加新的适应度函数
- Adding new runtime variables 增加新的运行时变量
预先准备
- A git client to check out the EvoSuite source code
- JDK (version 8)
- Apache Maven (version 3.1 or newer)
- An IDE (e.g., IntelliJ or Eclipse) in order to edit the source code
获取Evosuite的源码
1 | git clone https://github.com/EvoSuite/evosuite.git |
源代码被组织成几个Maven子模块。 也就是说,刚签出的源代码的主目录中有一个父pom.xml,然后在子目录中有几个单独的子项目。 让我们仔细看一下主要的子模块
master:EvoSuite使用主客户端架构,因为执行随机生成的测试时可能会出错(例如,我们可能会耗尽内存)。 客户端会不时地将当前的搜索结果发送到主进程,这样即使出现问题,最终我们仍然会进行一些测试。 主模块处理命令行上的用户输入(例如,解析命令行选项),然后生成客户端进程以进行实际的测试生成。
client:客户端承担了所有繁重的工作。 遗传算法位于此处,它是算法使用的测试用例和测试套件的内部表示形式,搜索运算符,执行测试用例的机制,生成跟踪信息以从中计算适用性值所需的所有字节码工具。
runtime:这是运行时库,即确定测试执行确定性所需的所有工具,模拟的Java API等。
plugins:这里有几个子项目,它们是各种第三方工具(如Maven,IntelliJ,Eclipse或Jenkins)的插件。
除了这些Maven模块之外,还有其他几个模块或子目录。 通常,您将不需要访问其中任何一个,但是如果您好奇它们是什么,则可以
standalone_runtime:该库中没有源代码,这只是一个Maven子模块,它生成一个独立的jar文件,即,其中包含运行时库的所有依赖项
shaded:这里也没有源代码。 这是一个Maven模块,它生成EvoSuite的版本,其中,包名称从org.evosuite重命名为其他名称。 这是为了允许将EvoSuite应用于自身(否则将无法正常运行,因为EvoSuite拒绝使用其自己的代码)。
generated:这是一个子模块,我们在其中放置EvoSuite生成的测试以测试EvoSuite。 这项工作仍在进行中。
release_results:这不是Maven子模块,它只是代表我们每次执行发布时在SF110数据集上进行的实验结果的数据集合。
src:这里没有Java源代码,只有一些与Maven相关的元数据。
removed:一些源代码文件未在主源代码树中使用,但对于保留作为参考很有用。
构建EvoSuite
1 | mvn compile |
IDE很可能会自动为您执行此操作。 但是,重要的是您的IDE支持Maven,并且已将项目配置为Maven项目。 如果您尚未执行此操作,则会收到错误消息,提示编译器无法在org.evosuite.xsd包中找到类。 jaxb会基于XML模式自动生成这些类,只有在您使用Maven正确编译了项目的情况下,才能完成这些类。
回顾本教程的第1部分,EvoSuite发行版包含两个jar文件-一个具有独立的运行时依赖项,另一个用于测试生成。 您可以通过调用以下命令生成它们:
1 | mvn package |
EvoSuite jar文件主要由以下主子模块生成:master / target / evosuite-master-1.0.4-SNAPSHOT.jar。 您可以通过使用Java调用可执行文件来验证这种情况。(这一步我就不做了。。)
1 | java -jar master/target/evosuite-master-1.0.4-SNAPSHOT.jar |
省略一部分,直接看扩展遗传算法
扩展遗传算法
现在,让我们对EvoSuite进行一些更改。 我们将考虑的第一个示例场景是实际的搜索算法。 您可能知道,EvoSuite使用遗传算法来驱动测试生成。 简而言之,这意味着存在大量候选解决方案(染色体,在这种情况下为测试套件),并且这些测试套件是使用旨在模拟自然进化的搜索运算符进行进化的。 适应度函数估计每个候选解决方案的质量。 优胜劣汰的个体繁殖的可能性最高,如果选择繁殖的个体,那么两个母体个体将使用交叉算子组合在一起以产生两个新的子孙个体,然后突变对这些子代进行较小的改变。
所有这些都在org.evosuite.ga软件包的客户端模块中实现。 有一个抽象的超类org.evosuite.ga.metaheuristics,然后有几个具体的实现,例如StandardGA,SteadyStateGA或EvoSuite的默认值MonotonicGA。 如果查看GeneticAlgorithm类,您将看到搜索算法具有很多成员,例如选择运算符selectionFunction,交叉运算符crossoverFunction和总体(种群)。 种群是一个列表,因为根据其适合度对个人进行排名; 该值由FitnessFunctions计算。 反过来,这是一个列表,因为EvoSuite通常同时使用多个适应功能,并且每个适应功能都有一个适应值。
如果您想了解有关遗传算法如何工作的更多详细信息,可以阅读[https://www.cs.colostate.edu/~genitor/MiscPubs/tutorial.pdf(或网络上无数的一些教程)。
如您所见,默认情况下,GeneticAlgorithm类使用SinglePointCrossOver实例化。 让我们仔细看看该类的外观–在编辑器中打开org.evosuite.ga.operators.crossover.SinglePointCrossover类。 该类扩展了抽象类CrossOverFunction,并实现了crossOver方法。 该方法接收两个个体作为父级,并随机选择两个交叉点point1和point2,两个个体中的每一个。 然后,它克隆了父母,并在生成的个体上调用了交叉方法来完成实际工作。 这就是元启发式搜索算法的优点:该算法与染色体代表的无关。
假设我们要实现一个替代的交叉算子,该算子总是在中间切掉染色体,而现有的交叉算子全都选择随机的交换点。 让我们在客户端模块(文件client / src / main / java / org / evosuite / ga / operators / crossover / MiddleCrossOver.java)中创建一个新的Java类org.evosuite.ga.operators.crossover.MiddleCrossOver。 该类应扩展抽象类CrossOverFunction,这意味着它必须实现方法crossOver。 因此,骨架看起来像这样
1 | package org.evosuite.ga.operators.crossover; |
为了实现这种交叉功能,我们需要了解一个重要方面:遗传算法的教科书示例通常会假设染色体中固定数量的基因。 但是,与遗传算法的许多其他标准应用程序不同,EvoSuite中的个体大小可能会有所不同,因为我们甚至在开始搜索之前就无法知道正确数量的测试用例。 因此,每个个体的“中间”是不同的
它行得通吗? 让我们写一个测试案例来找出答案。 让我们添加一个新文件client / src / test / java / org / evosuite / ga / operators / crossover / MiddleCrossOverTest.java。
客户端模块中的测试具有用于测试的DummyChromosome实现。 DummyChromosome需要一个整数列表,并进行突变和交叉。 例如,我们可以为不同大小(例如4和2)的父母创建,然后检查生成的个体是否具有正确的基因。 例如,测试可能如下所示
添加新的覆盖率标准和适应度函数
例如正交测试(pairwise testing)中我们要覆盖所有的方法调用对。
1 | public class Foo { |
根据默认的覆盖标准,EvoSuite的目标是尽可能全面覆盖这三种方法。 有了成对方法覆盖的新思想,我们希望EvoSuite还可以创建对象,这些对象依次调用bar和foo,bar和zoo以及foo和zoo。
EvoSuite中的覆盖标准作为适应性函数实现。 对于每个覆盖标准,有三个主要类别
- Test suite适应度函数,该准则指导在测试套件空间中进行搜索,以实现对准则的完全覆盖。
- Test case适应度函数,它指导在测试用例空间中进行搜索,以实现单个覆盖目标。 这也可用于确定测试套件是否涵盖单个覆盖目标。
- Test goal factory,产生一组测试用例的适应度函数,当测试套件覆盖了每个测试用例的适应度函数时,同时,这些测试套件也有最佳适应度函数。
您可以在org.evosuite.coverage包的客户端模块中找到大量示例。
让我们添加一个新包:org.evosuite.coverage.methodpair。 我们将从为单个测试添加适应度函数开始。 尽管EvoSuite的默认设置是演化测试套件而不是单个测试,但是EvoSuite也可以演化包含个体的种群,例如,使用基线方法-generateTests,或使用新的多目标“ MOSA”方法-generateMOSuite。 此外,即使EvoSuite开发了测试套件,所有后处理都要求将覆盖标准表示为一组测试适用性函数。 创建类org.evosuite.coverage.methodpair.MethodPairTestFitness。 此类将从org.evosuite.testcase.TestFitnessFunction继承
1 | public class MethodPairTestFitness extends TestFitnessFunction { |
到目前为止,这很容易。适应度函数功能的主要部分是getFitness方法,我们必须重写该方法。
这是重载的方法;有一个版本将TestChromosome作为输入,而另一个版本将TestChromosome和ExecutionResult作为输入。
org.evosuite.testcase.TestChromosome类是方法调用序列的遗传编码。
如果查看该类,将看到它包含类org.evosuite.testcase.TestCase的测试用例,然后TestChromosome的主要功能在于mutate和crossover方法。
反过来,TestCase接口由org.evosuite.testcase.DefaultTestCase类实现,该类由org.evosuite.testcase.Statement实现的列表组成。在org.evosuite.testcase.statements包中实现了各种不同类型的语句,最好再仔细研究一下该包。对于每个语句类,最关键的功能可能是execute方法的实现,这是Java Reflectionon用于执行测试的地方。每个语句类还利用许多VariableReference实例-这些是测试中使用的变量,并指向由测试的语句创建的对象。在EvoSuite中,每个语句都创建一个这样的VariableReference-无效方法调用除外。
为了创建method-pair覆盖率,我们需要看的两个语句是ConstructorStatement和MethodStatement。顾名思义,它们分别调用构造函数和方法。此信息由以下三种方法提供:getDeclaringClass,getMethodName和getDescriptor。什么是描述符?描述符表示方法所采用的参数及其返回的值(请参阅[StackOverflow说明(http://stackoverflow.com/questions/7526483/what-is-the-difference-between-descriptor-and-signature)]] )。例如,如果我们有一个方法将两个整数作为输入并返回一个布尔值,则描述符将为“(II)Z”,其中I代表一个整数,Z则为布尔值。对我们而言,最重要的是描述符使我们能够区分重载方法。由于这通常需要在EvoSuite中完成,因此在大多数情况下,EvoSuite实际上使用方法名称和描述符的串联,而不仅仅是普通方法名称。
org.evosuite.coverage.methodpair.MethodPairFactory
1 | public class MethodPairFactory extends AbstractFitnessFactory<MethodPairTestFitness> { |
MethodPairSuiteFitness
1 | public class MethodPairSuiteFitness extends TestSuiteFitnessFunction { |
具体参考官网哦,十分详细的http://www.evosuite.org/documentation/tutorial-part-4/
我也正在研究这部分,有兴趣的可以一起交流~
最后附上我的pom.xml文件的最终配置
1 | <?xml version="1.0" encoding="UTF-8"?> |